RAG Chatbot - Chat with PDF
Transform your PDFs into intelligent conversational assistants. Ask questions, extract insights, and get instant answers from your documents using advanced Retrieval Augmented Generation (RAG) technology.

Powerful Features
Everything you need for intelligent document interaction
Advanced AI Understanding
Powered by GPT-4 Turbo for deep comprehension and accurate responses
Persistent Memory
Vector database stores all document knowledge for instant retrieval
Real-time Responses
Sub-second query processing with streaming responses
Enterprise Security
End-to-end encryption, SOC 2 compliant infrastructure
Multi-format Support
PDFs, Word docs, presentations, and more
24/7 Availability
Always-on chatbot accessible from anywhere
N8N Workflow Architecture
Complete RAG pipeline from document upload to intelligent responses
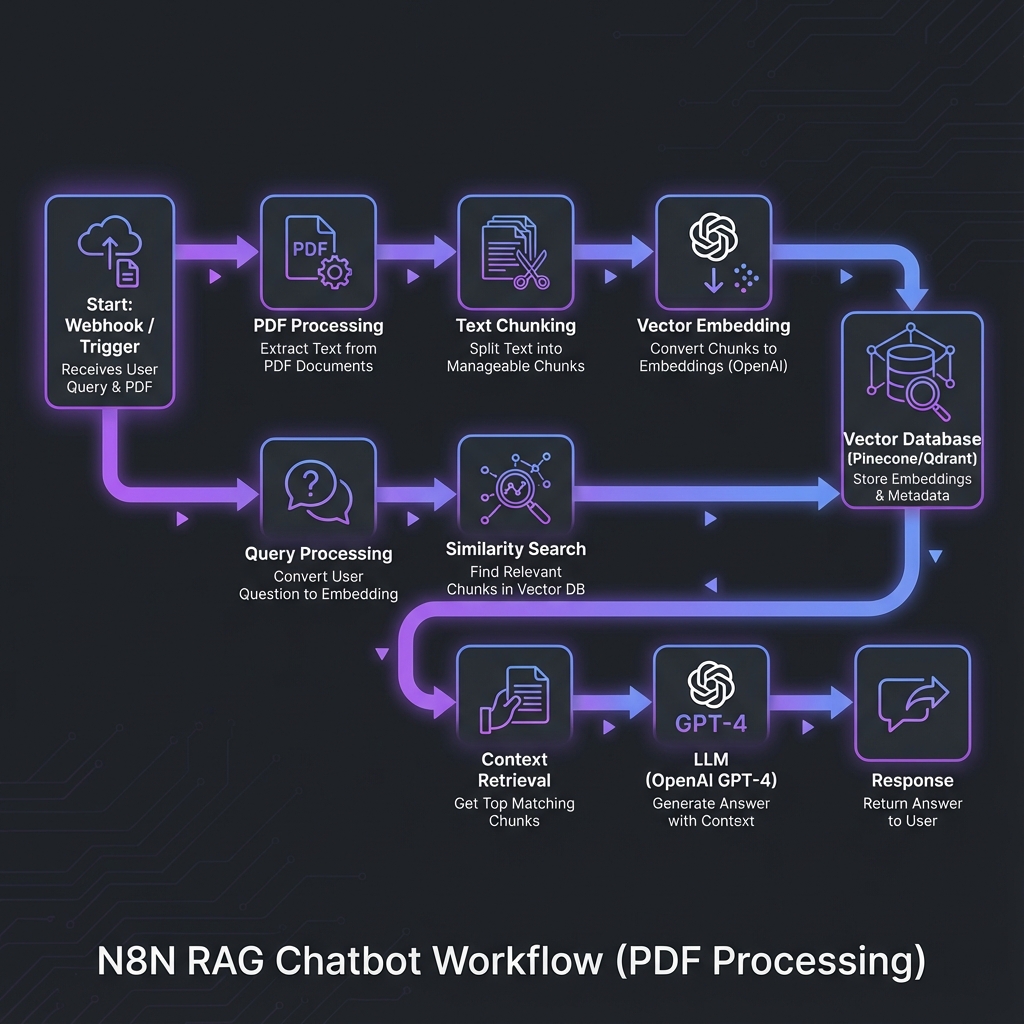
Document Processing Pipeline
- 1.PDF upload via webhook trigger
- 2.Text extraction and OCR processing
- 3.Intelligent chunking with overlap
- 4.Vector embedding generation (OpenAI)
- 5.Storage in Pinecone vector database
Query Processing Pipeline
- 1.User query received via chat interface
- 2.Query embedding generation
- 3.Semantic similarity search in vector DB
- 4.Context retrieval and re-ranking
- 5.GPT-4 answer generation with citations
How It Works
Discover the technology behind intelligent document conversations
Document Upload & Processing
Intelligent PDF parsing and text extraction
Intelligent Text Chunking
Smart segmentation for optimal retrieval
Vector Embedding & Storage
High-performance semantic search infrastructure
Contextual Query Processing
Advanced RAG pipeline for accurate answers
Transform Your Business Operations
See how businesses leverage RAG chatbots across industries to boost efficiency, reduce costs, and unlock new insights.
Legal Document Analysis
Quickly extract insights from contracts, case files, and legal briefs
Research & Academia
Accelerate literature review and research paper analysis
Customer Support
Instant answers from product manuals and documentation
Financial Services
Analyze reports, statements, and regulatory documents
Technical Specifications
AI Models
- Embedding Model:text-embedding-3-large
- LLM:GPT-4 Turbo
- Context Window:128K tokens
- Embedding Dimensions:3072
Infrastructure
- Vector Database:Pinecone
- Orchestration:N8N
- Max Document Size:100 MB
- Supported Formats:PDF, DOCX, TXT
Ready to Transform Your Documents?
Join hundreds of businesses using RAG chatbots to unlock insights from their documents. Start your free trial today.
No credit card required • 14-day free trial • Cancel anytime
Ask AI
Opens in a new tab • Auto Prompt